

Controllability at Scale: The Missing North Star for Autonomous Deployments
Autonomy is a capability. Controllability is the requirement that makes autonomy deployable.

Most autonomous deployments don’t fail in the lab. They fail the first time someone asks a simple question in a room that matters:
“Why did it do that — and what can we do about it?”
If your answer is a mix of log files, probability distributions, and “we’ll patch it,” you don’t have a scalable system. You have a high-performing prototype with a governance gap.
This is the part the autonomy conversation tends to skip.
We spend enormous energy on autonomy as a capability: perception, planning, policies, models, sensors, edge inference. That work matters. But capability is not the gating factor once you move from pilots to production.
The gating factor is controllability
Not the illusion of control through dashboards. Not a kill switch. Not “human-in-the-loop” as a checkbox.
Controllability is the architecture that keeps autonomous deployments governable, safe, and accountable as complexity accelerates.
The question isn’t “can it operate?”
It’s “can we govern it when it does?”
Autonomy is a capability. Controllability is the requirement.
Here is the shift I wish more autonomy leaders made earlier:
Autonomy answers: Can the system perform the task?
Controllability answers: Can the organization stay in charge of the system at scale?
Autonomous deployments become real when they hit the things demos avoid:
degraded connectivity
sensor drift
ambiguous rules
unexpected human behavior
conflicting priorities
partial failures (not total failures)
regulatory and board scrutiny
The models assumes the world is mostly stable and exceptions are rare.
Reality is the opposite: exceptions are the product.
If your autonomous deployment can’t be exercised and enforced through exceptions, it cannot scale. It will either be frozen by risk owners, or it will scale until it breaks trust — and then get frozen anyway.
The common failure pattern: capability first, governance later
Most teams build autonomous deployments in a familiar sequence:
Prove the model works
Increase autonomy
Scale the deployment
Add governance “when needed”
This sequence is backwards. Governance can’t be bolted on after the system has already defined:
what counts as a valid action
who has authority to override
what evidence is captured
how rollbacks work
what “safe mode” actually means
When governance is an afterthought, failures look mysterious and political:
engineers say the system was “within expected behavior”
operators say the system was “unpredictable”
risk says “pause the rollout”
leadership says “we’re not ready for autonomy”
The technology didn’t fail. The deployment failed because control was never designed as a first-class requirement.
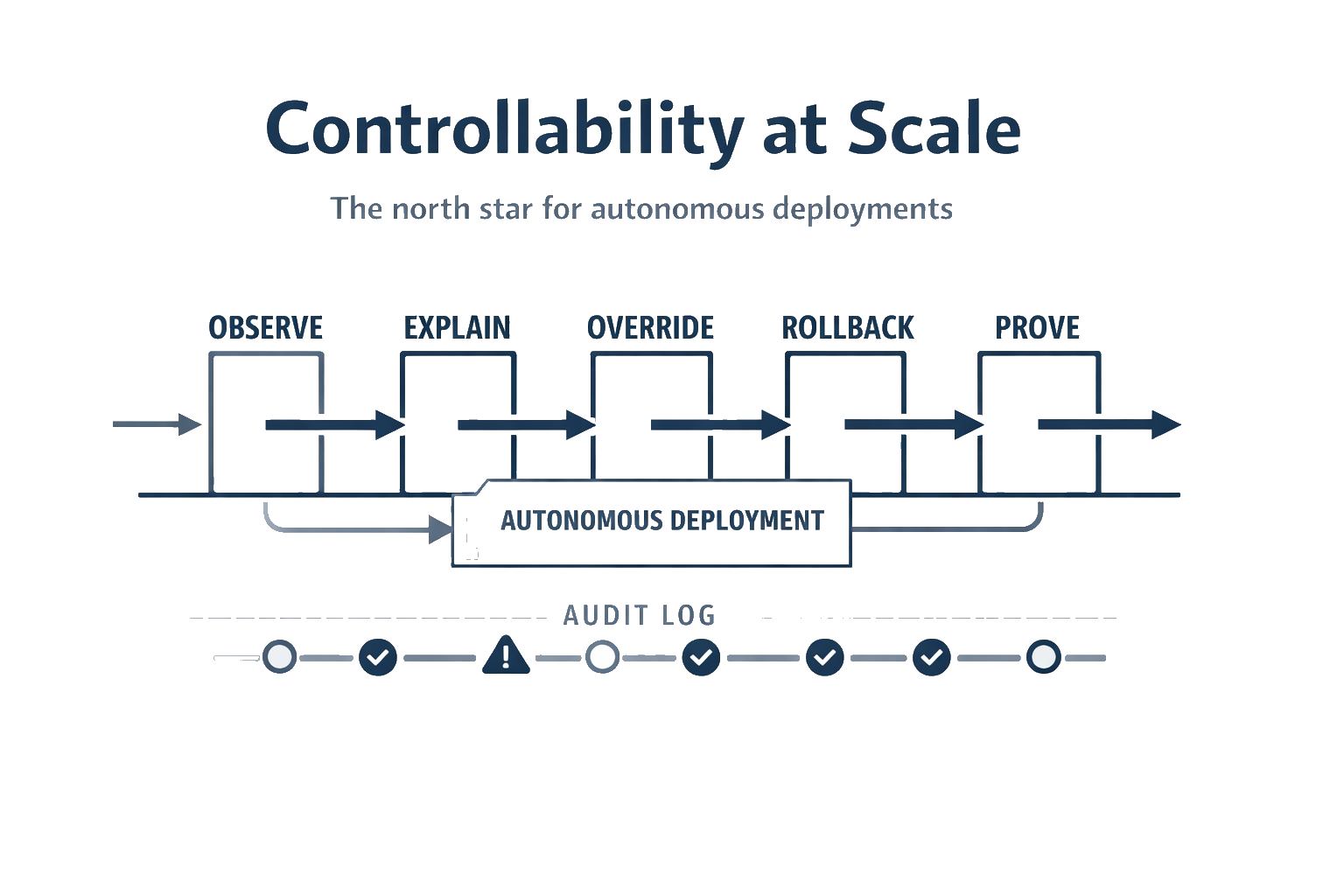
A practical definition: controllability at scale
I use a simple definition:
Controllability at scale means an autonomous deployment remains observable, explainable, governable, reversible, and auditable as its scope expands.
That’s still abstract, so let’s make it operational.
If you’re responsible for autonomous deployments (or approving them), you want to know:
Can we see what the system is doing in time to intervene?
Can we explain decisions to humans who own consequences?
Can we override decisions with clear authority and low friction?
Can we roll back behavior safely when something goes wrong?
Can we prove what happened after the fact with evidence that stands up to scrutiny?
Those are not “nice to have” features.
They are the difference between a controlled deployment and a liability.
Appendix
The controllability scorecard: 5 tests every autonomous deployment should pass
Below is a scorecard I’ve found useful across autonomous and hybrid human–machine systems.
Score each test from 0 to 2:
0 = missing / informal / only works in ideal conditions
1 = partial / manual / works sometimes
2 = designed-in / reliable / exercised regularly
You don’t need 10/10 to start.
But if you’re trying to scale autonomous deployments with a 3/10 controllability posture, you’re not moving fast. You’re accumulating shutdown debt.
Test 1 — Observe: Can we see state and intent in time to act?
What “pass” looks like (2/2):
You can see the system’s current state, active constraints and confidence/uncertainty.
Telemetry isn’t just raw metrics; it’s operationally meaningful.
You can detect when the system is outside its expected operating envelope.
Common failure mode:
The autonomous deployment “looks fine” right until it isn’t.
You get outcomes (late deliveries, near misses, policy violations), but you can’t see the leading indicators. Operators rely on gut feel and ad-hoc screenshots.
What to build (practical):
clear state model (what state is the system in?)
envelope monitoring (what conditions are allowed?)
uncertainty surfaced as a signal (not hidden)
event timelines that operators can actually read
Observation is not about having more dashboards.
It’s about being able to answer: “What is it doing right now, and is that allowed?”
Test 2 — Explain: Can it produce a human-usable rationale?
Explainability is commonly treated as a machine learning problem.
In practice, it’s a governance problem.
What “pass” looks like (2/2):
For any material action, the system can output:
what it observed
what rules/constraints were active
what options it considered
why it chose one over the others
what it would do if conditions changed
Not a research-grade interpretability report.
A human-usable decision narrative.
Common failure mode:
After an incident, you can reconstruct a story only by stitching together logs. That’s not explainability — that’s archaeology.
Worse: different teams reconstruct different stories, and governance turns into a debate about whose narrative is “true.”
What to build (practical):
decision summaries as first-class outputs (“decision receipts”)
conflict/uncertainty flags (“this was a low-confidence choice”)
operator-facing explanations, not engineer-facing traces
If you can’t explain decisions, scaling will be blocked by the people who carry consequences: safety, operations, compliance, boards.
Test 3 — Override: Can authorized humans (or policies) intervene, cleanly?
“Human-in-the-loop” is often a slogan. Override is an architecture requirement.
What “pass” looks like (2/2):
Clear authority: who can override what, under which conditions.
Low-friction intervention: the system doesn’t fight the override.
Multiple override levels:
immediate stop/hold
policy constraint changes
reroute / reassign
escalation to a human supervisor
Common failure mode:
Overrides exist but are unusable:
too slow (latency, approvals)
too blunt (only “stop everything”)
too informal (operators text an engineer)
too risky (override breaks other systems)
In that world, people will bypass the system. That’s not safety.
That’s ungoverned autonomy hidden behind a UI.
What to build (practical):
explicit override pathways (tested, trained, and logged)
escalation thresholds (ambiguity, novelty, risk)
separation of powers (operator vs supervisor vs safety officer)
A scalable autonomous deployment is autonomous within constraints — and constraints require enforcement plus intervention paths.
Test 4 — Rollback: Can we revert behavior safely and predictably?
Most autonomy teams treat rollback as an engineering hygiene issue. At scale, rollback is a governance primitive.
What “pass” looks like (2/2):
You can revert model/config/behavior in minutes, not days.
“Safe mode” is defined and exercised.
You can roll back partially (one region, one fleet segment, one workflow).
Common failure mode:
A deployment goes wrong and your only options are:
keep running and hope it stabilizes
shut down everything
Both create organizational trauma. Trauma kills scaling.
What to build (practical):
versioned policies and configs with controlled rollout
canary deployments and staged rollout gates
rollback playbooks that operators can execute
Rollback is how you turn “we learned something” into “we improved safely.”
Test 5 — Prove (Evidence): Can we demonstrate what happened to a board or regulator?
This is the test many teams ignore until it is too late.
What “pass” looks like (2/2):
You can produce evidence for a specific decision:
inputs used (and their quality)
constraints active at the time
decision record and rationale
overrides applied (by whom, when, why)
post-incident analysis with traceability
Common failure mode:
Your post-incident package is a narrative:
“the system behaved unexpectedly”
“we are committed to safety”
“we will implement improvements”
That language may be sincere. But it is not evidence. And without evidence, trust does not compound.
What to build (practical):
decision receipts stored immutably (with access controls)
audit-ready timelines
clear ownership of evidence production
If you can’t prove what happened, you can’t scale autonomous deployments into regulated environments — and you can’t defend them when something inevitably goes wrong.
A simple way to use the scorecard
If you want this to be actionable, don’t start by scoring “autonomy maturity.”Start by scoring controllability on a specific autonomous deployment.
Step 1: Pick one deployment that matters
Choose a deployment where the consequences are real:
safety implications
customer trust
compliance exposure
significant cost impact
Step 2: Score 0–2 on each test
Do it with a cross-functional group:
engineering
operations
safety / risk
(if relevant) compliance
The goal isn’t consensus by debate. The goal is to surface where control is informal or imaginary.
Step 3: Fix the weakest link before scaling
Controllability behaves like a chain.
If you can observe and explain but can’t override, you still don’t have control. If you can override but can’t roll back safely, you’ll avoid overriding.
If you can do all of that but can’t prove what happened, scaling will be blocked by governance and trust.
Step 4: Treat “exceptions” as design inputs, not embarrassment
Every override, escalation, and rollback is a governance signal.
If your autonomous deployment needs frequent human intervention, that is not a reason to hide humans.
It is a reason to:
formalize the intervention pathway
tighten constraints
improve observation
reduce ambiguity
Govern what you automate — before scale makes it brittle.
Why controllability increases speed (not bureaucracy)
Teams often fear that governance will slow them down. In my experience, the opposite is true.
Autonomous deployments move slowly when they produce organizational fear:
“We don’t understand why it did that.”
“We can’t stop it without stopping everything.”
“We can’t explain this to our regulator / board / customer.”
Fear creates pauses.
Pauses create backlogs.
Backlogs create shadow operations.
Shadow operations create incidents.
Controllability breaks this loop.
When you can observe, explain, override, roll back, and prove — you can ship faster because:
incidents are contained instead of existential
learning loops are shorter
rollouts can be staged safely
approvals become repeatable
This is why I call controllability a north star.
It makes autonomy deployable.
The closing question (the one that predicts scale)
If you want one question to pressure-test your readiness for scaled autonomous deployments, use this:
If a board member or regulator asked you tomorrow to justify this autonomous deployment, what evidence could you show within 24 hours?
If the honest answer is “we’d need time to pull logs and reconstruct it,” your next investment should not be more autonomy.
It should be more controllability.
Summary takeaways
Autonomy is a capability; controllability is the deployability requirement.
Controllability at scale can be tested with five questions: observe, explain, override, rollback, prove (evidence).
The goal is not perfect autonomy; it is autonomous deployments that remain governable under real-world variability.
Controllability increases speed by preventing shutdown cycles and building institutional trust.
Discussion questions
Which controllability test is weakest in your current autonomous deployments?
What would you need to show a regulator or board tomorrow?
Where do overrides happen today — and are they treated as governance signals or informal heroics?
Autonomy fails quietly. Loss of trust does not